 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Sort Eval: Efficient Preference Evaluation for Visual Generation via Corrected VLM-as-a-Judge
Feb 10, 2026The rapid development of visual generative models raises the need for more scalable and human-aligned evaluation methods. While the crowdsourced Arena platforms offer human preference assessments by collecting human votes, they are costly and time-consuming, inherently limiting their scalability. Leveraging vision-language model (VLMs) as substitutes for manual judgments presents a promising solution. However, the inherent hallucinations and biases of VLMs hinder alignment with human preferences, thus compromising evaluation reliability. Additionally, the static evaluation approach lead to low efficiency. In this paper, we propose K-Sort Eval, a reliable and efficient VLM-based evaluation framework that integrates posterior correction and dynamic matching. Specifically, we curate a high-quality dataset from thousands of human votes in K-Sort Arena, with each instance containing the outputs and rankings of K models. When evaluating a new model, it undergoes (K+1)-wise free-for-all comparisons with existing models, and the VLM provide the rankings. To enhance alignment and reliability, we propose a posterior correction method, which adaptively corrects the posterior probability in Bayesian updating based on the consistency between the VLM prediction and human supervision. Moreover, we propose a dynamic matching strategy, which balances uncertainty and diversity to maximize the expected benefit of each comparison, thus ensuring more efficient evaluation. Extensive experiments show that K-Sort Eval delivers evaluation results consistent with K-Sort Arena, typically requiring fewer than 90 model runs, demonstrating both its efficiency and reliability.
Multi-Granular Attention based Heterogeneous Hypergraph Neural Network
May 07, 2025



Heterogeneous graph neural networks (HeteGNNs) have demonstrated strong abilities to learn node representations by effectively extracting complex structural and semantic information in heterogeneous graphs. Most of the prevailing HeteGNNs follow the neighborhood aggregation paradigm, leveraging meta-path based message passing to learn latent node representations. However, due to the pairwise nature of meta-paths, these models fail to capture high-order relations among nodes, resulting in suboptimal performance. Additionally, the challenge of ``over-squashing'', where long-range message passing in HeteGNNs leads to severe information distortion, further limits the efficacy of these models. To address these limitations, this paper proposes MGA-HHN, a Multi-Granular Attention based Heterogeneous Hypergraph Neural Network for heterogeneous graph representation learning. MGA-HHN introduces two key innovations: (1) a novel approach for constructing meta-path based heterogeneous hypergraphs that explicitly models higher-order semantic information in heterogeneous graphs through multiple views, and (2) a multi-granular attention mechanism that operates at both the node and hyperedge levels. This mechanism enables the model to capture fine-grained interactions among nodes sharing the same semantic context within a hyperedge type, while preserving the diversity of semantics across different hyperedge types. As such, MGA-HHN effectively mitigates long-range message distortion and generates more expressive node representations. Extensive experiments on real-world benchmark datasets demonstrate that MGA-HHN outperforms state-of-the-art models, showcasing its effectiveness in node classification, node clustering and visualization tasks.
An Item is Worth a Prompt: Versatile Image Editing with Disentangled Control
Mar 07, 2024Building on the success of text-to-image diffusion models (DPMs), image editing is an important application to enable human interaction with AI-generated content. Among various editing methods, editing within the prompt space gains more attention due to its capacity and simplicity of controlling semantics. However, since diffusion models are commonly pretrained on descriptive text captions, direct editing of words in text prompts usually leads to completely different generated images, violating the requirements for image editing. On the other hand, existing editing methods usually consider introducing spatial masks to preserve the identity of unedited regions, which are usually ignored by DPMs and therefore lead to inharmonic editing results. Targeting these two challenges, in this work, we propose to disentangle the comprehensive image-prompt interaction into several item-prompt interactions, with each item linked to a special learned prompt. The resulting framework, named D-Edit, is based on pretrained diffusion models with cross-attention layers disentangled and adopts a two-step optimization to build item-prompt associations. Versatile image editing can then be applied to specific items by manipulating the corresponding prompts. We demonstrate state-of-the-art results in four types of editing operations including image-based, text-based, mask-based editing, and item removal, covering most types of editing applications, all within a single unified framework. Notably, D-Edit is the first framework that can (1) achieve item editing through mask editing and (2) combine image and text-based editing. We demonstrate the quality and versatility of the editing results for a diverse collection of images through both qualitative and quantitative evaluations.
Integrating View Conditions for Image Synthesis
Oct 26, 2023In the field of image processing, applying intricate semantic modifications within existing images remains an enduring challenge. This paper introduces a pioneering framework that integrates viewpoint information to enhance the control of image editing tasks. By surveying existing object editing methodologies, we distill three essential criteria, consistency, controllability, and harmony, that should be met for an image editing method. In contrast to previous approaches, our method takes the lead in satisfying all three requirements for addressing the challenge of image synthesis. Through comprehensive experiments, encompassing both quantitative assessments and qualitative comparisons with contemporary state-of-the-art methods, we present compelling evidence of our framework's superior performance across multiple dimensions. This work establishes a promising avenue for advancing image synthesis techniques and empowering precise object modifications while preserving the visual coherence of the entire composition.
UnrealNAS: Can We Search Neural Architectures with Unreal Data?
May 19, 2022
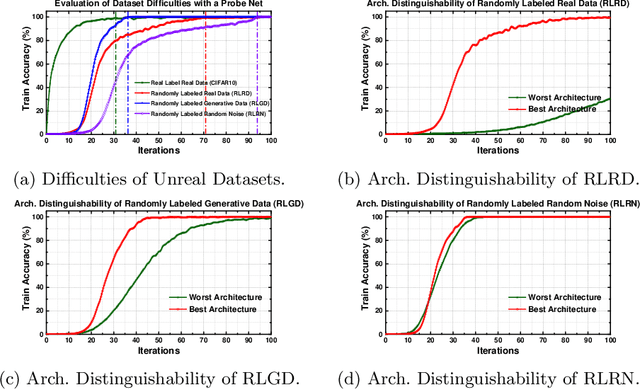
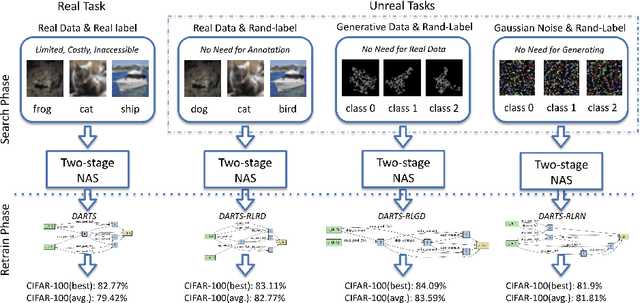
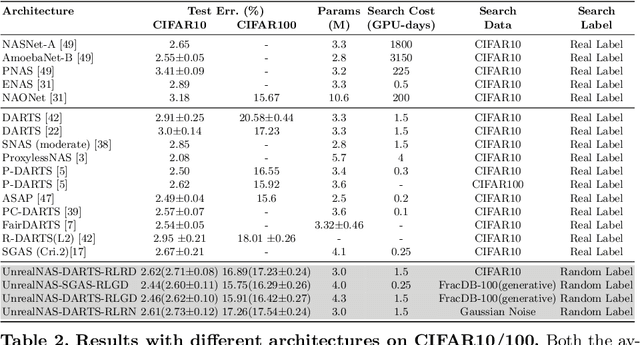
Neural architecture search (NAS) has shown great success in the automatic design of deep neural networks (DNNs). However, the best way to use data to search network architectures is still unclear and under exploration. Previous work has analyzed the necessity of having ground-truth labels in NAS and inspired broad interest. In this work, we take a further step to question whether real data is necessary for NAS to be effective. The answer to this question is important for applications with limited amount of accessible data, and can help people improve NAS by leveraging the extra flexibility of data generation. To explore if NAS needs real data, we construct three types of unreal datasets using: 1) randomly labeled real images; 2) generated images and labels; and 3) generated Gaussian noise with random labels. These datasets facilitate to analyze the generalization and expressivity of the searched architectures. We study the performance of architectures searched on these constructed datasets using popular differentiable NAS methods. Extensive experiments on CIFAR, ImageNet and CheXpert show that the searched architectures can achieve promising results compared with those derived from the conventional NAS pipeline with real labeled data, suggesting the feasibility of performing NAS with unreal data.